Make Your Own Kind of Map
Simple Tooling for Simpler Package Management
Introduction
Welcome back to the wondrous world of package management.
You’ll recall we started exploring this world after pip,
Python’s package manager, switched to a new package resolver that strictly
adheres to version constraints and package installation suddenly might take
hours when before it took seconds.
Our exploration revealed a big world of harsh terrain that’s infested with dragons and all kinds of other ferociously dangerous critters. Yet there are few maps of this world and they all suffer from significant inaccuracies and omissions. So we channeled our inner Isidore of Seville and set out to more completely and accurately map the world of package management.
In this second installment, we’ll talk about why you should maintain your own custom maps and leverage them to prevent dragon infestations. And I’ll share how, to solve the dilemma that started this quest, we transformed a simple script for extracting package requirements from 34 version control repositories into a checking tool that is based on the dragon-repellent design of Go’s package manager and validates every merge request for those 34 repositories.
The Evolution of Enigma’s Package Dependency Checker Tool
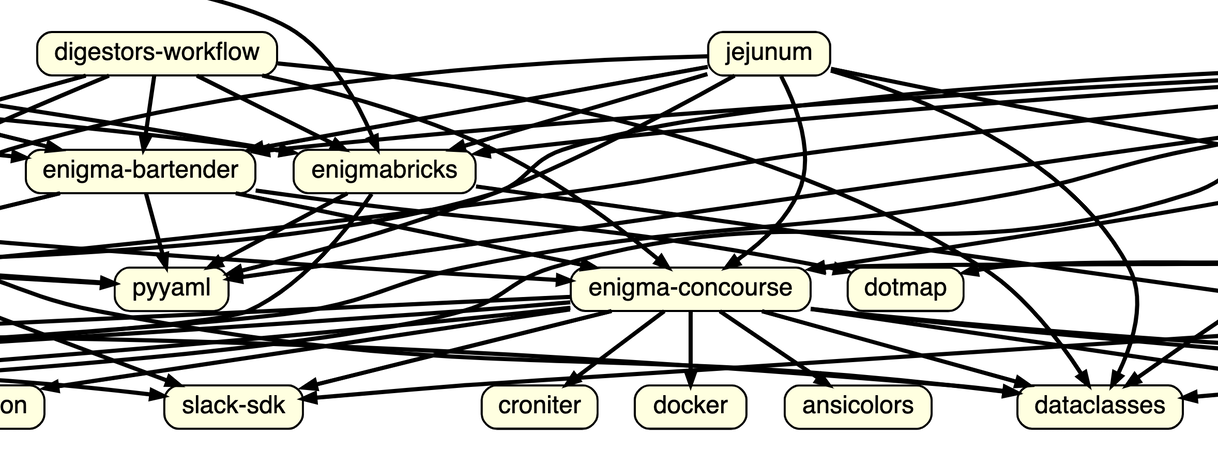
I hope that you agree by now that Python package management is like catnip for dragons or dragonwort and hence irresistible to those ferocious buggers. But that knowledge — by itself — doesn’t really help us.
As we covered in the first post, I set out to locate the specific dragons hiding amongst the Python package requirements of the 15 tasks and 19 internal libraries in our small business data processing pipeline and wrote a script to avoid the tedium of manually inspecting 34 repositories. The first version of the script already used the GitLab API to extract each project’s requirements files as well as Artifactory’s API to extract the list of internal distributions. It then parsed the requirements, combined them into a global dependency graph, and tried to generate a visual representation with the Graphviz tool.
Alas, that first version also had three minor shortcomings: The code was rough. There were no tests. It didn’t work.
Ahem—let’s be more precise: after some initial effort, Graphviz did produce a faithful visual representation of the dependency graph. But as you can see above, that representation had an uncanny resemblance to an angry toddler’s doodle. Reorienting the drawing order from Graphviz’s default top-down to left-right, sorting nodes in topological order (graphlib in Python’s standard library is truly awesome), and then declaring nodes before edges all improved visual clarity. But the resulting graph still wasn’t actually useful: it now resembled a high school student’s first technical drawing assignment — after that student got so frustrated two-thirds through, they went into angry-toddler-doodling mode. It appears that our package dependency graph simply is too complicated for visual representation.
Luckily, my tech lead had run the script himself and noticed that it was also
generating two text files. I had added generation logic for debugging purposes,
with both files formatted in glorious Markdown. One file listed the dependency
graph just as in requirements.txt files, that is, all dependents
organized by dependee or required organized by requirer, and the other file
listed the graph organized by dependents, listing the dependees or requirers.
That second file turned out to be the perfect dragonbane by making the
identification of inconsistent requirements trivial: it listed all version
constraints for the same package, one under the other.
I created the necessary issues for manually cleaning up the
requirements.txt files and, over the next few sprints, the entire
team chipped in to get them done. We even beat our internal deadline, thanks to
my script and because our dragon infestation was smaller than we feared — as it
turns out, dragons produce a lot of smoke but not that much fire.
With that infestation handled, Enigma’s CTO immediately asked how we planned to prevent recurrences. Thus the project scope grew to include a checking tool that would run as part of every merge request and keep requirements consistent. That implied three areas for improvement:
- First, we needed internal consistency checks, since the dependency checker relied on a manually configured list of pipeline repositories and such secondary sources of truth have the annoying habit of becoming inconsistent with reality. That may still happen with the consistency checks in place, but the tool fails with an error message identifying the package missing from the internal package list.
- Second, we needed a better graph representation with a uniform representation for edges to simplify traversal of the dependency graph in both directions, i.e., from dependent to dependee and from dependee to dependent.
- Third, we needed unit tests, ideally lots of them.
While we worked on making those changes a reality, I explored what exact checks our dependency checker tool should enforce over a weekend. Given that Python’s version satisfiability is NP-complete, I considered building a symbolic reasoning engine on top of the SymPy package but realized that option was far too ambitious. Then I recalled seeing Russ Cox’s series of blog posts on Go’s module system a few months prior and revisited them, poring over the gory details.
Go’s package manager makes a novel trade-off between the expressivity of the version constraints and computational complexity, while also producing predictable results. Its starting point is semantic versioning, which provides clear rules for version number increases: increment the third, patch number for bug fixes, the second, minor number for new features, and the first, major number for backwards-incompatible changes. It then imposes four more restrictions:
- Version constraints are limited to minimum version constraints, i.e., the
>=operator in Python. - Major version updates require that the name of the package be changed as well. This corresponds to an implied maximum version constraint on the next major version.
- Applications may additionally pin or exclude specific versions; these extra constraints are ignored when the same package is used as a library.
- Instead of picking the latest package version, which may change over time, Go’s package manager always picks the oldest version fulfilling the version constraints.
None of these restrictions are onerous. The rules of semantic versioning are simple enough. Minimum version constraints are sufficient for capturing the features and bug fixes required for a package. Major version upgrades are already difficult and always require care, only now package maintainers feel more of the pain of backwards-incompatible changes — just as it should be. And appending, say, “v2” to the name of your package isn’t too difficult either.
At the same time, the benefits are tremendous: semantic versioning clearly communicates the expected impact of a package update. Go’s package manager can compute suitable versions in linear time (which is much faster than for NP-complete algorithms). It always arrives at the same solution, even if new package versions have been released in the meantime.
Fantastic! I found a realistic blueprint for realistic package management.
But given the realistic engineering constraints of a startup, I had to make some
pragmatic choices in realizing this blueprint. So I decided to punt on minimum
version selection for now. Writing a wrapper script for pip would
have to wait for another day.
I also decided to limit Python’s environment markers to constraining Python versions only and to partitioning the version space into two. A quick glance at the output of the dependency checker reassured me that this restriction was realistic and wouldn’t break any of our existing uses of environment markers. The restriction implies that checking the consistency of version constraints on a given package may have to be performed twice, once for each partition.
Finally, I decided to stick to the Go blueprint when it comes to version constraints and to allow minimum version constraints on release versions only, with an optional maximum version constraint on the next major version and no dev, pre, and post versions.
The resulting dependency checker tool comprises a little more than 2,600 lines of well-documented Python code (not counting tests) and has been running in continuous integration for a couple of months now in advisory mode. During that time, we fixed at least one bug — our ontology contains data, not code, and thus does not require dependency checking — and some but not all of the reported errors.
At the time of writing this blog post, 21 out of 34 repositories still include some non-compliant version constraints. Because there are so many affected repositories and fixing them all would require a clear commitment, some engineers have argued to just cut our losses and loosen the restrictions enforced by the tool.
The primary cause of contention is Python’s compatible release operator ~=.
It really is syntactic sugar for a pair of minimum and maximum version
constraints. That works out well when the operator is applied to a version
number consisting of major and minor version only, since, say,
~=3.4 translates to >=3.4, <4.0 or
>=3.4.0, <4.0.0 and thus is perfectly consistent
with Go’s restrictions. But when the compatible release operator is applied to a
version number consisting of a patch version too, it is inconsistent with those
same restrictions. For instance, ~=3.4.5 translates to
>=3.4.5, <3.5.0, i.e., includes a maximum
version constraint on the minor version. The latter case makes up the vast
majority of remaining errors reported by our dependency checker tool.
The pushback against fixing every affected repository serves as a useful reminder that enabling a new coding tool is only the beginning of the deployment process. It also requires generating buy-in from developers. In fact, we might just conclude that package management isn’t only a technical challenge but also a social one.
That’s just the topic of the third blog post in this series.